Running some Caffe examples on CPU and GPU
So we have Caffe compiled, and with the support from CUDA & cuDNN, we can take avantage of our GPU to speed up the learning process significantly. But, that’s just what we have been told so far. When we speak about the performance term, the words “good”, “faster”, “much faster” or even “significantly faster” are way too subtle and not much informative. In order to answer the question “How faster?”, it’s better to consider the difference in computing time between CPU Mode and GPU Mode. I will use two datasets which Caffe provided the trained models: MNIST and CIFAR-10 for comparing purpose. Note that in this post, I just consider the size of the dataset for simplicity, without considering the complexity of the Networks. I will dig more further about it on future posts on Neural Network.
MNIST test on CPU vs GPU
First, make sure you are in the root folder of Caffe, and run the commands below to download the MNIST dataset:
cd $CAFFE_ROOT
./data/mnist/get_mnist.sh
./examples/mnist/create_mnist.sh
That’s all we have to do to prepare the data. Let’s see how much time the CPU need to run each iteration:
./build/tools/caffe time --model=examples/mnist/lenet_train_test.prototxt
And here’s my result on my Intel Core i7-6700K CPU:
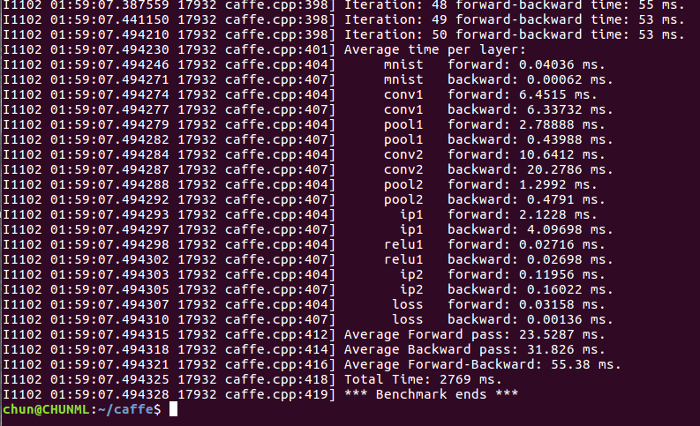
As you can see, my CPU took approximately 55ms to run each iteration, in which 23ms for forward pass and 32ms for backward pass. Let’s go ahead and see if the GPU can do better:
./build/tools/caffe time --model=examples/mnist/lenet_train_test.prototxt --gpu 0
And here’s the result on my GTX 1070:
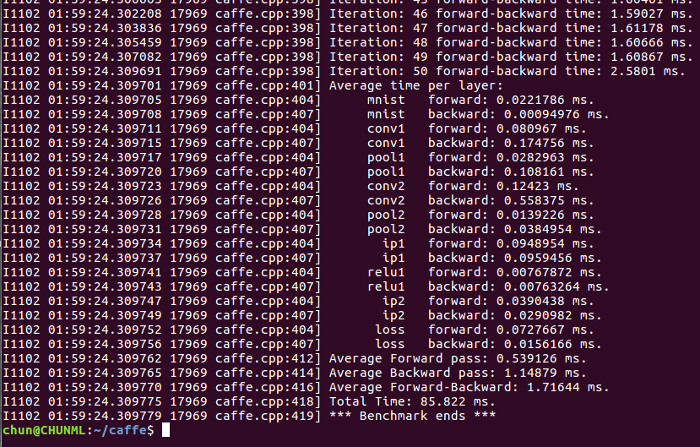
The result came out nearly right after I hit Enter. I was really impressed, I admit. Each iteration took only 1.7ms to complete, in which 0.5ms for forward pass and 1.2ms for backpropagation. Let’s do some calculation here: the computing time when using GPU is roughly 32 times faster than when using CPU. Hmm, not so bad, you may think.
Because MNIST dataset is pretty small in size, which each example is just a 28x28 grayscale image, and it contains only 70000 images in total, the CPU still can give us an acceptable performance. Also note that in order to make use of the power of GPU, our computer has to take some times to transfer data to the GPU, so with small dataset and simple Network, the difference between the two may not be easily seen.
Let’s go ahead and give them a more challenging one.
CIFAR10 test on CPU vs GPU
First, make sure you are in the root folder of Caffe, and run the commands below to download the CIFAR-10 dataset:
cd $CAFFE_ROOT
./data/cifar10/get_cifar10.sh
./examples/cifar10/create_cifar10.sh
CIFAR-10 is way larger comparing to MNIST. It contains 60000 32x32 color images, which means CIFAR-10 is roughly three times larger than MNIST. That’s a real challenge for both to overcome, right?.
Just like what we did with MNIST dataset, let’s first see how much time it takes using CPU:
./build/tools/caffe time --model=examples/cifar10/cifar10_full_train_test.prototxt
And here’s the result I got:
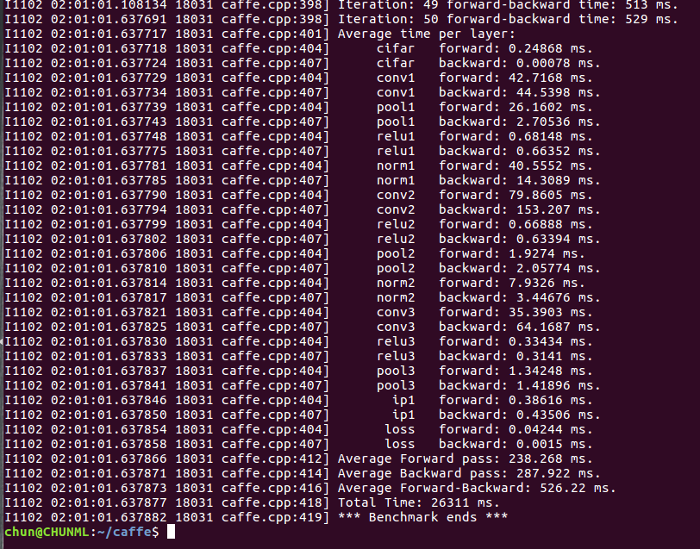
As you can see, with a larger dataset (and a more complicated Network, of course), the computing speed was much slower comparing with MNIST dataset. It took approximately 526ms to complete one iteration: 238ms for forward pass and 288ms for backward pass. Let’s go ahead and see how well the big guy can do:
./build/tools/caffe time --model=examples/cifar10/cifar10_full_train_test.prototxt --gpu 0
And the result I had with my GTX 1070:
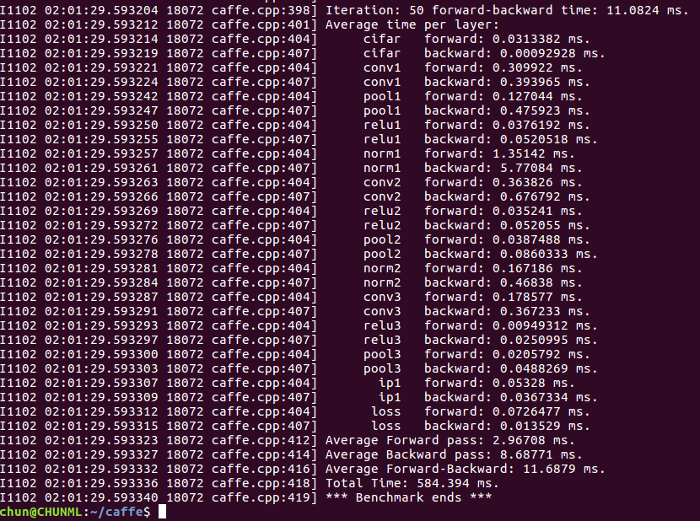
Look at the result above. Unlike the significant decrease in performance as we saw when running on CPU, my GTX 1070 still brought me an impressive computing speed. It took only 11ms on one iteration, in which 3ms for forward pass and 8ms for backpropagation. So when running on CIFAR-10 dataset, the GPU really did outperform the CPU, which computed 48 times faster. Imagine you are working with some real large dataset in real life such as ImageNet, using GPU would save you a great deal of time (let’s say days or even weeks) on training. The faster you obtain the result, the more you can spend on improving the Model. That’s also the reason why Neural Network, especially Deep Neural Network, has become the biggest trend in Machine Learning after long time being ignored by the lack of computing power. Obviously not only nowadays, but Deep Neural Network will continue to grow in the future.
Resources
- https://chunml.github.io/ChunML.github.io/project/Installing-Caffe-CPU-Only/.