Real-time face detection using Haar cascades on a Raspberry Pi
Face recognition from image or video is a popular topic in biometrics research. Many public places usually have surveillance cameras for video capture and these cameras have their significant value for security purpose. It is widely acknowledged that the face recognition have played an important role in surveillance system as it doesn’t need the object’s cooperation. As human face is a dynamic object having high degree of variability in its appearance, that makes face detection a difficult problem in computer vision. In this field, accuracy and speed of identification is a main issue.
Face detection can be classified into two classes (face and non-face). Most applications are based on face recognition and tracking. These applications needs to locate the position of the face in the image or video. Moreover, face detection has added a much needed aspect of security in the recent years. Biometric systems, a front sided camera (Selfie) of a smart phone, human presence detection are some of the key implementations of face detection. Basically face detection senses the presence of the face in a 2D frame. Hence the detection of human face is possible. Several methods and approaches are developed for face detection.
Viola-Jones Algorithm
The Viola–Jones object detection algorithm is the first object detection algorithm to provide competitive object detection rates in real-time proposed in 2001 by Paul Viola and Michael Jones. Although it can be trained to detect a variety of object classes, it was motivated primarily by the problem of face detection.
The problem to be solved is detection of faces in an image. A human can do this easily, but a computer needs precise instructions and constraints. To make the task more manageable, Viola–Jones requires full view frontal upright faces. Thus in order to be detected, the entire face must point towards the camera and should not be tilted to either side. While it seems these constraints could diminish the algorithm's utility somewhat, because the detection step is most often followed by a recognition step, in practice these limits on pose are quite acceptable.
This approach to face detecting combines four key concepts:
a. Haar-like features: simple rectangular features.
b. Integral image: for rapid features detection.
c. AdaBoost: machine-learning method.
d. Cascade classifier: to combine many features efficiently.

Figure 1: Viola-Jones steps
A. Haar like features:
Haar like features are used to detect variation in the black and light portion of the image. This computation forms a single rectangle around the detected face. Based on the color shade near nose or forehead a contour is formed. Some commonly used Haar features are: two rectangle feature, three rectangle feature, four rectangle feature.
The value of two rectangle feature is the difference between the sums of the pixels within two rectangle regions as sown in Figure 2. In three rectangles, the value is center rectangle subtracted by the addition of the two surrounding rectangles. Whereas four rectangle features computes the difference between the diagonal pairs of the rectangles.

Figure 2: Haar features used for face detection
B. Integral Images:
As the name suggests, the value at any point (x, y) in the summed-area table is the sum of all the pixels above and to the left of (x, y), inclusive:
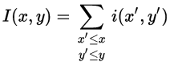
where i(x,y) is the value of the pixel at (x,y).
The summed-area table can be computed efficiently in a single pass over the image, as the value in the summed-area table at (x, y) is just:
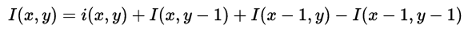
Once the summed-area table has been computed, evaluating the sum of intensities over any rectangular area requires exactly four array references regardless of the area size. That is, the notation in the figure at right, having A=(x0, y0), B=(x1, y0), C=(x0, y1) and D=(x1, y1), the sum of i(x,y) over the rectangle spanned by A, B,C and D is:
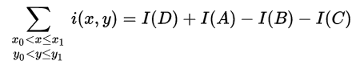
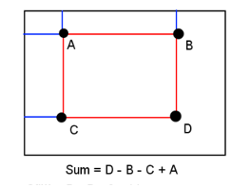
Figure 3: A description of computing a sum in the summed-area table data structure/algorithm
C. Adaboost machine learning method
AdaBoost algorithm helps to select small features from the face that facilitates fast and easy computation. Unlike other methods, AdaBoost algorithm gives desired region of the object discarding unnecessary background.
It uses an important concept of Bagging that is procedure for combining different classifiers constructed using the same data set.It is an acronym for bootstrap aggregating, a motivation of combining classifiers is to improve an unstable classifier and an unstable classifier is one where a small change in the learning set/classification parameters produces a large change in the classifier.
The speed with which features may be evaluated does not adequately compensate for their number, however. For example, in a standard 24x24 pixel sub-window, there are a total of M = 162,336 possible features, and it would be prohibitively expensive to evaluate them all when testing an image. Thus, the object detection framework employs a variant of the learning algorithm AdaBoost to both select the best features and to train classifiers that use them. This algorithm constructs a “strong” classifier as a linear combination of weighted simple “weak” classifiers.
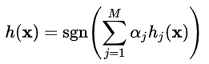
Each weak classifier is a threshold function based on the feature fj.
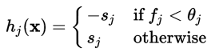
The threshold value θj and the polarity sj are determined in the training, as well as the coefficients αj.
D. Cascade classifier
The Viola and Jones face detection algorithm eliminates face candidates quickly using a cascade of stages. The cascade eliminates candidates by making stricter requirements in each stage with later stages being much more difficult for a candidate to pass. Candidates exit the cascade if they pass all stages or fail any stage. A face is detected if a candidate passes all stages. This process is shown in Figure 4.
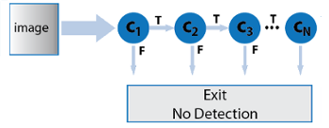
Figure 4: Cascades using for face detection
Implementation
The evaluation of a strong classifiers generated by a learning process can be done quickly, but it isn’t fast enough to run in real-time over a frame of images. For this reason, the strong classifiers are arranged in a cascade in order of complexity, where each successive classifier is trained only on those selected samples which pass through the preceding classifiers. If at any stage in the cascade a classifier rejects the sub-window under inspection, no further processing is performed and continue on searching the next sub-window. The cascade therefore has the form of a degenerate tree.
However, when using the Raspberry Pi for Viola-Jones algorithm we have two major pitfalls working against us: restricted memory (only 1GB on the Raspberry Pi 3) and limited processor speed (four ARM Cortex-A53 core running at 1.2GHz on the Raspberry Pi 3). So, this makes it difficult to use larger, complex algorithms on this platform. Since Viola-Jones algorithm was designed to perform face detection using the least amount of computational resources, the impementation on the Raspberry Pi 3 board is feasible. The Figure 5 shows the scheme of the face detection system.

Figure 5: Basic scheme of the face detection system
The detection process is as follows: first, the stream video is obtained using the Pi Camera module and using the Raspicam library, then the frames of the video are converted from RGB to Grayscale to process faster the face detection algorithm. Finally, histogram equalization is done before to apply face detection algorithm. Histogram equalization technique improves the contrast in an image, in order to stretch out the intensity range.
After histogram equalization, multiscale face detection is performed, this mens that the Raspberry Pi platforms performs face detection on diferent scales using the trained model. This detection for each captured image is realized using the libraries of OpenCV 2.4 (works with 3.3.0 version too). In addition, this implementation was performed completely in C++. A basic scheme of the recognition system is presented in the Figure 6 and show the input and output signals:
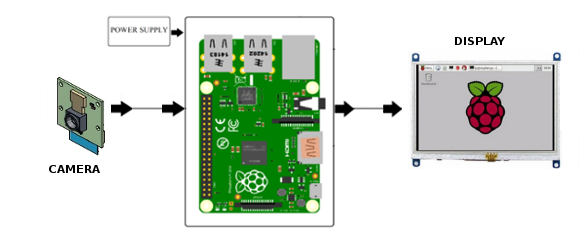
Figure 6: Basic scheme of the face detection system
Results
As the video shows, the face detection is performed in real-time. The face detected is show in a red square. Furthermore, this video shows robustness of the trained model to small rotations and shiftings as well as stability. On the other hand, the time to complete face detection is about 267.66 miliseconds (average from 10 iterations) since Viola-Jones algorithm is evaluated in the whole image.
Face detector in real-time running on a Raspberry Pi
In summary, a face detector was implemented in real-time on a Raspberry Pi platform. The testing phase shows a good detection for different rotations, positions and light conditions. In addition to this, the time used to perform the image classification for each image is about 267.66 ms. This precessing time can be reduced by using tracking algorithms like the KLT algorithm to detect salient features within the detection bounding boxes and track their movement between frames.