Basic examples of Convolutional Neural Networks
In machine learning, a convolutional neural network (CNN, or ConvNet) is a class of deep, feed-forward artificial neural networks that has successfully been applied to analyzing visual imagery. CNNs use relatively little pre-processing compared to other image classification algorithms. This means that the network learns the filters that in traditional algorithms were hand-engineered. This independence from prior knowledge and human effort in feature design is a major advantage. A CNN consists of an input and an output layer, as well as multiple hidden layers. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, fully connected layers and normalization layers.
The model used in this project is a modification of a LeNet neural network. The parameters and weights were obtained after training step. The training phase is show in the Figure 1. This training is performed usig the Caffe framework. The design and layers of the model is described in the .prototxt file and the parameters of this training is contained in the .caffemodel file. After training step, the .prototxt and .caffemodel files will be used on a laptop machine in order to perform inference. The Figure 2 show the inference step.
Figure 1: Training phase
Figure 2: Inference phase
The total number of classes used for classification will depend of the application (2 outputs for the first application 'playing musical instruments' and 3 outputs for the second application 'rock–paper–scissors hand game') and are composed by simple hand gestures such as open hand or simple shapes formed with the fingers. Some examples of the hand poses used for classification are showed in the Figure 3. Since hand region is usually exposed to different conditions such as luminance variations and skin tone, a pre-processing step is needed to extract the hand in order to perform correct classification of hand poses. So, a RGB-Binary conversion based on skin thresholding is used to extract hand features before to apply the convolutional neural network classifier.

Figure 3: RGB and binary images of the hand poses
The architecture of the simple CNN used in this project is illustrated in the Figure 4. This architecture is a modification of the LeNet-5 architecture. This basic arhitecture was taken as reference since the images have a low resolution (48x48 pixels) and requires few convolutional layers for classification. As the figure shows, this proposed architecture is composed of two convolutional layers, two sub-sampling layers and three simple full-conection layers.
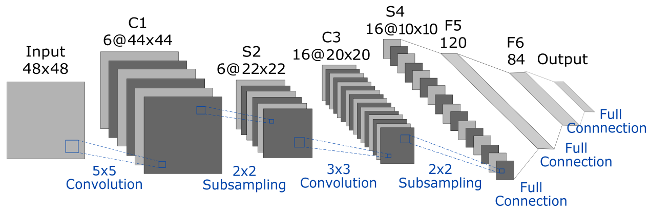
Figure 4: Architecture of the Convolutional Neural Network used for Hand Pose Detection
The number of images are 7000 (for training) and 1000 (for testing) for each class, and are based on a single person. These hand poses have different shapes, rotations, shiftings, and scales in order to obtain a robust model able to deal with different conditions for hand pose classification in real time.
After training and testing prediction statistics are evaluated in order to analyse the correct classification of the trained model. As mentioned above, a single person is used for testing and training for simplicity. The accuracy of the recognition system is the mean value of 10 iterations. The performance of the recognition systems shows an accuracy of 99.8% for the first application 'playing musical instruments' and 95.6% for the second application 'rock–paper–scissors hand game'.
The implementation of the whole system was performed in C++ and using OpenCV 3.3.0 libraries since these allow the easy realization of loading caffe models with a good performance. Also, these libraries can be used on a personal computer as well as on different embedded computers like Beglebone and Raspberry Pi.
As the videos show, the recognition of hand poses is performed in real-time. The first step consists in hand detection. The binary image of the hand is used as input of the Convolutional Neural Network to perform hand pose classification. The Video 1 shows the implementation of the first application 'playing musical instruments' on a personal computer. Also, the video demostrates the robustness of the recognition to small rotations and shiftings as well as stability. In addition, the time to single image classification takes about 0.67 miliseconds (average from 10 iterations).
Video 1: Simple game based on playing musical instruments
The Video 2 shows the implementation of the second application 'rock–paper–scissors hand game' on a personal computer. As expected, the processing time is similar to the first application, so the time to single image classification takes about 0.88 miliseconds (average from 10 iterations).
Video 2: Simple game based on rock–paper–scissors hand game
To sum up, two applications based on hand gesture classification using Convolutional Neural Netwoeks were implemented in real-time on a personal computer. The testing phase show an accuracy of 99.8% and 95.6% for the first and second application respectively. In addition to this, the time used to perform the image classification for each image is about 0.7 ms on a personal computer since we are using few classes for classification. Also, additional funny examples can be implemented based on gesture classification and using Convolutional Neural Networks.