Basic hand pose recognition system on a PC using CNNs
Introduction
Over the las decades, computer vision and neural networks (NN) techniques have played an increasingly important role in the design of pattern recognition systems. Examples of this include from transport systems (e.g. self-driving cars) to medicine (e.g. detectors of tumors). This increase in the number of applications is due the development of novel techniques of Artificial Intelligence such as Convolutional Neural Networks (CNN), which model animal visual perception and have become the method of choice for processing visual and other two-dimensional data.
Hand gesture recognition is a challenging topic of research due to the increasing demands for robotics in recent years. Gesture recognition based on visual perception has many advantages over devices such as sensors, or electronic gloves. Hand gesture recognition provides users with an intuitive means of directly using their hands to interact with a robot. In addition to this, hand gestures can be applied to virtual reality environments, image/video coding, content-based image/video retrieval, and video games.
Implementation
Since hand region is usually exposed to different conditions such as luminance variations and skin tone, a pre-processing step is needed to extract the hand in order to perform correct classification of hand poses. So, a RGB-Binary conversion based on skin thresholding is used to extract hand region. This pre-processing step will be applied to the RGB images (captured from camera) before going through the convolutional neural network. The procedure described above is showed in the Figure 1.
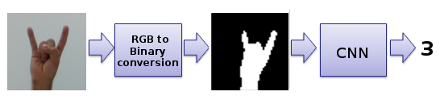
Figure 1: Basic schema of pre-processing step and classification
The total number of classes used for classification will be five and are composed by simple hand gestures such as open hand or simple shapes formed with the fingers. These hand poses used for classification is showed in the Figure 2. Furthermore, binary images will be used as input of the convolutional neural network for training, testing and inference.

Figure 2: RGB and binary images of the hand poses
For the model construction training phase will be performed. This step consists on the optimization of the parameters of the model for correct gand pose classification. So, gradient ascent algorithm, which is a first-order iterative optimization algorithm for finding the minimum of a function, is used by the CNN to extract the optimized values of the network.
After training step, a testing phase is requiered in order to evaluate the accuracy and precision of the constructed model. For this, the model will be evaluated with images different from those used in the training phase. Usually, the number of images to perform testing is ~20% of the total training images. The steps of training and testing is illustrated in the Figure 3.
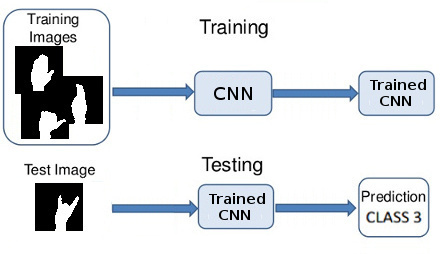
Figure 3: Architecture of the Convolutional Neural Network used for Hand Pose Detection
The architecture of the simple CNN used in this project is illustrated in the Figure 4. This architecture is similar to LeNet-5 architecture. This basic arhitecture was taken as reference due the ability to process higher resolution images requires larger and more convolutional layers, so this technique is constrained by the limited availability of computing resources. As the figure shows, this proposed architecture is composed of two convolutional layers, two sub-sampling layers and three simple full-conection layers.
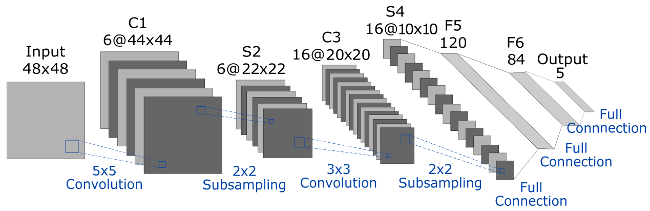
Figure 4: Architecture of the Convolutional Neural Network used for Hand Pose Detection
The total number of images is 41400 and is composed by 7 persons (from Person 1 to 7). These hand poses have different shapes, rotations, shiftings, and scales in order to obtain a robust model able to deal with different conditions for hand pose classification in real time.
Cross-validation is useful in regimes where the dataset is small or moderate and the not much training data can be held out to reliably estimate test performance. This is not usually the case with deep learning where the amount of data is huge and holding out a reasonable portion of it for testing is not an issue. Therefore, this deep leartning project will not use cross-validation.
In this project person-independent testing will be performed. So, Person 3 will be used for testing and Person 1, 2, 4, 5, 6, 7 will be used for training. Therefore, 36000 images for training and 5400 for testing. Figure 5 shows this distribution of data.
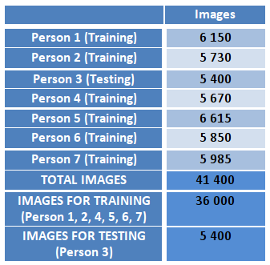
Figure 5: Distribution of the images
Caffe (Convolution Architecture For Feature Extraction) was selected after the evaluation of the pos and cons of these frameworks. The principal advantages of this framework is that their expressive architecture encourages application and innovation, furthermore, Caffe has pre trained model that facilitate the design of CNNs. In addition to this, Caffe already powers academic research projects, startup prototypes, and even large-scale industrial applications in vision, speech, and multimedia.
There are 4 steps in training a CNN using Caffe:
Step 1: Data preparation: In this step, we clean the images and store them in a format that can be used by Caffe.
Step 2: Model definition: In this step, we choose a CNN architecture and we define its parameters in a configuration file with extension .prototxt.
Step 3: Solver definition: The solver is responsible for model optimization. We define the solver parameters in a configuration file with extension .prototxt.
Step 4: Model training: We train the model by executing one Caffe command from the terminal. After training the model, we will get the trained model in a file with extension .caffemodel.
After training step, the .prototxt and .caffemodel files will be used to make predictions of new unseen data. We will write a Python script to this.
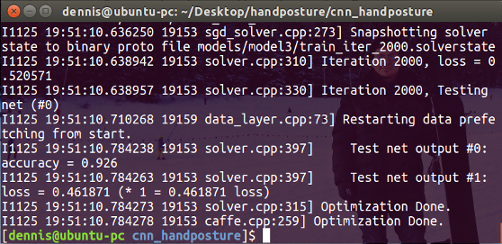
Figure 6: Training phase using Caffe framework
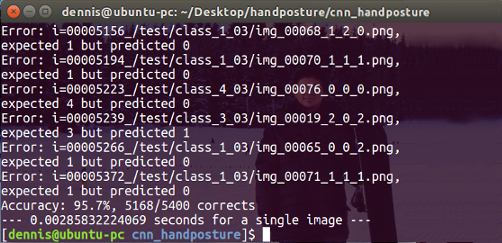
Figure 7: Test phase using Python script and Caffe framework
Results
After training and testing prediction statistics are evaluated in order to analyse the correct classification of the trained model. As mentioned above, Person 3 is used to peform person-independent testing. The accuracy of the recognition system is the mean value of 10 iterations. This mean value and other parameters are show in the Figure 8. The performance of the recognition system shows an accuracy of 86.5% since the neural network is small and the binary images used for training does not give important imformation for feature extraction of the convolutional neural network.
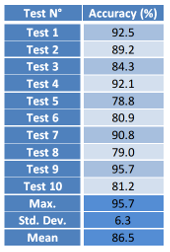
Figure 8: Accuracy using 10 iterations (10 tests)
Another prediction stradistic is the confusion matrix, which is often used to describe the performance of a classification model. This matrix is very important because gives useful information about the true and predicted classes, and helps to find the classes where the trained model performs wrong classification.
The confusion matrix used to evaluate the trained model for hand pose detection is showed in the Figure 9. Two important features of the confusion matrix is the Precision and Recall. Precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances, while Recall (also known as sensitivity) is the fraction of relevant instances that have been retrieved over the total amount of relevant instances.
The confusion matrix of the trained model shows a relative lower precision for the class 1. Indeed, this lower precision is a product of the prediction of the class 0 instead of the class 1. As confusion matrix shows, about 10% of the data of the class 1 is wrong classified as class 0 since these two classes have similarities of the shape in the binary images and is difficult to the trained model to differentiate these shapes.
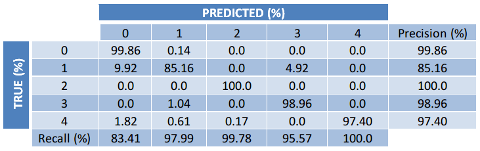
Figure 9: Confusion matrix for the best accuracy (95.7%)
Despite the wrong classification of the trained model for some classes, the accuracy is high and allows the correct classification of hand poses. In addition to this, the Figure 7 shows good processing time, wish is about 2.6 ms for a single image. It should be noted that it was implemented on a laptop machine with high computational resources (8 cores @ 2.80GHz). So, this allows the implementation in real-time.
The real-time hand pose detector was implemented in python and using Caffe libraries to perform prediction. Also, one additional implementation was performed in C++ and using OpenCV 3.3.0 libraries, the results were the same. As the video shows, the recognition of hand poses is performed in real-time. It also shows robustness to small rotations and shiftings as well as stability.

Figure 10: Hand poses and labels
Hand Pose Detector in Real Time running on a laptop
Conclusions
In this project, a hand pose detector was implemented in real-time. The prediction stradistic show a good accuracy for the classification of 5 hand poses. In addition to this, the time used to perform the image classification for each image is about 2.6 ms. The accuracy can be improved by adding more training images, adding filters or image transormations in pre-processing step as well as adding mode convolutional layers and tunning the model. Also, additional techniques for skin detection can be added in order to have a better hand pose detector.