Image processing using CUDA and OpenCV on Linux
This code depends on:
- G++.
- OpenCV 2.3+.
- CUDA 4.0+ sdk.
This code should work on any Unix like system (Mac OS X and Linux) as long as you have the nvcc compiler and g++ compiler in your binary path and OpenCV 2.3 installed in a place with default paths (/usr on Ubuntu, /usr/local on a Mac).
Code
Create the file
//
// Created by Nathaniel Lewis on 3/8/12.
// Copyright (c) 2012 E1FTW Games. All rights reserved.
//
#include <iostream>
#include <string>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
// GPU constant memory to hold our kernels (extremely fast access time)
__constant__ float convolutionKernelStore[256];
/**
* Convolution function for cuda. Destination is expected to have the same width/height as source, but there will be a border
* of floor(kWidth/2) pixels left and right and floor(kHeight/2) pixels top and bottom
*
* @param source Source image host pinned memory pointer
* @param width Source image width
* @param height Source image height
* @param paddingX source image padding along x
* @param paddingY source image padding along y
* @param kOffset offset into kernel store constant memory
* @param kWidth kernel width
* @param kHeight kernel height
* @param destination Destination image host pinned memory pointer
*/
__global__ void convolve(unsigned char *source, int width, int height, int paddingX, int paddingY, ssize_t kOffset, int kWidth, int kHeight, unsigned char *destination)
{
// Calculate our pixel's location
int x = (blockIdx.x * blockDim.x) + threadIdx.x;
int y = (blockIdx.y * blockDim.y) + threadIdx.y;
float sum = 0.0;
int pWidth = kWidth/2;
int pHeight = kHeight/2;
// Only execute for valid pixels
if(x >= pWidth+paddingX &&
y >= pHeight+paddingY &&
x < (blockDim.x * gridDim.x)-pWidth-paddingX &&
y < (blockDim.y * gridDim.y)-pHeight-paddingY)
{
for(int j = -pHeight; j <= pHeight; j++)
{
for(int i = -pWidth; i <= pWidth; i++)
{
// Sample the weight for this location
int ki = (i+pWidth);
int kj = (j+pHeight);
float w = convolutionKernelStore[(kj * kWidth) + ki + kOffset];
sum += w * float(source[((y+j) * width) + (x+i)]);
}
}
}
// Average the sum
destination[(y * width) + x] = (unsigned char) sum;
}
// converts the pythagoran theorem along a vector on the GPU
__global__ void pythagoras(unsigned char *a, unsigned char *b, unsigned char *c)
{
int idx = (blockIdx.x * blockDim.x) + threadIdx.x;
float af = float(a[idx]);
float bf = float(b[idx]);
c[idx] = (unsigned char) sqrtf(af*af + bf*bf);
}
// create an image buffer. return host ptr, pass out device pointer through pointer to pointer
unsigned char* createImageBuffer(unsigned int bytes, unsigned char **devicePtr)
{
unsigned char *ptr = NULL;
cudaSetDeviceFlags(cudaDeviceMapHost);
cudaHostAlloc(&ptr, bytes, cudaHostAllocMapped);
cudaHostGetDevicePointer(devicePtr, ptr, 0);
return ptr;
}
int main (int argc, char** argv)
{
// Open a webcamera
cv::VideoCapture camera(0);
cv::Mat frame;
if(!camera.isOpened())
return -1;
// Create the capture windows
cv::namedWindow("Source");
cv::namedWindow("Greyscale");
cv::namedWindow("Blurred");
cv::namedWindow("Sobel");
// Create the cuda event timers
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// Create the gaussian kernel (sum = 159)
const float gaussianKernel5x5[25] =
{
2.f/159.f, 4.f/159.f, 5.f/159.f, 4.f/159.f, 2.f/159.f,
4.f/159.f, 9.f/159.f, 12.f/159.f, 9.f/159.f, 4.f/159.f,
5.f/159.f, 12.f/159.f, 15.f/159.f, 12.f/159.f, 5.f/159.f,
4.f/159.f, 9.f/159.f, 12.f/159.f, 9.f/159.f, 4.f/159.f,
2.f/159.f, 4.f/159.f, 5.f/159.f, 4.f/159.f, 2.f/159.f,
};
cudaMemcpyToSymbol(convolutionKernelStore, gaussianKernel5x5, sizeof(gaussianKernel5x5), 0);
const ssize_t gaussianKernel5x5Offset = 0;
// Sobel gradient kernels
const float sobelGradientX[9] =
{
-1.f, 0.f, 1.f,
-2.f, 0.f, 2.f,
-1.f, 0.f, 1.f,
};
const float sobelGradientY[9] =
{
1.f, 2.f, 1.f,
0.f, 0.f, 0.f,
-1.f, -2.f, -1.f,
};
cudaMemcpyToSymbol(convolutionKernelStore, sobelGradientX, sizeof(sobelGradientX), sizeof(gaussianKernel5x5));
cudaMemcpyToSymbol(convolutionKernelStore, sobelGradientY, sizeof(sobelGradientY), sizeof(gaussianKernel5x5) + sizeof(sobelGradientX));
const ssize_t sobelGradientXOffset = sizeof(gaussianKernel5x5)/sizeof(float);
const ssize_t sobelGradientYOffset = sizeof(sobelGradientX)/sizeof(float) + sobelGradientXOffset;
// Create CPU/GPU shared images - one for the initial and one for the result
camera >> frame;
unsigned char *sourceDataDevice, *blurredDataDevice, *edgesDataDevice;
cv::Mat source (frame.size(), CV_8U, createImageBuffer(frame.size().width * frame.size().height, &sourceDataDevice));
cv::Mat blurred (frame.size(), CV_8U, createImageBuffer(frame.size().width * frame.size().height, &blurredDataDevice));
cv::Mat edges (frame.size(), CV_8U, createImageBuffer(frame.size().width * frame.size().height, &edgesDataDevice));
// Create two temporary images (for holding sobel gradients)
unsigned char *deviceGradientX, *deviceGradientY;
cudaMalloc(&deviceGradientX, frame.size().width * frame.size().height);
cudaMalloc(&deviceGradientY, frame.size().width * frame.size().height);
// Loop while capturing images
while(1)
{
// Capture the image and store a gray conversion to the gpu
camera >> frame;
cv::cvtColor(frame, source, CV_BGR2GRAY);
// Record the time it takes to process
cudaEventRecord(start);
{
// convolution kernel launch parameters
dim3 cblocks (frame.size().width / 16, frame.size().height / 16);
dim3 cthreads(16, 16);
// pythagoran kernel launch paramters
dim3 pblocks (frame.size().width * frame.size().height / 256);
dim3 pthreads(256, 1);
// Perform the gaussian blur (first kernel in store @ 0)
convolve<<<cblocks,cthreads>>>(sourceDataDevice, frame.size().width, frame.size().height, 0, 0, gaussianKernel5x5Offset, 5, 5, blurredDataDevice);
// Perform the sobel gradient convolutions (x&y padding is now 2 because there is a border of 2 around a 5x5 gaussian filtered image)
convolve<<<cblocks,cthreads>>>(blurredDataDevice, frame.size().width, frame.size().height, 2, 2, sobelGradientXOffset, 3, 3, deviceGradientX);
convolve<<<cblocks,cthreads>>>(blurredDataDevice, frame.size().width, frame.size().height, 2, 2, sobelGradientYOffset, 3, 3, deviceGradientY);
pythagoras<<<pblocks,pthreads>>>(deviceGradientX, deviceGradientY, edgesDataDevice);
cudaThreadSynchronize();
}
cudaEventRecord(stop);
// Display the elapsed time
float ms = 0.0f;
cudaEventSynchronize(stop);
cudaEventElapsedTime(&ms, start, stop);
std::cout << "Elapsed GPU time: " << ms << " milliseconds" << std::endl;
// Show the results
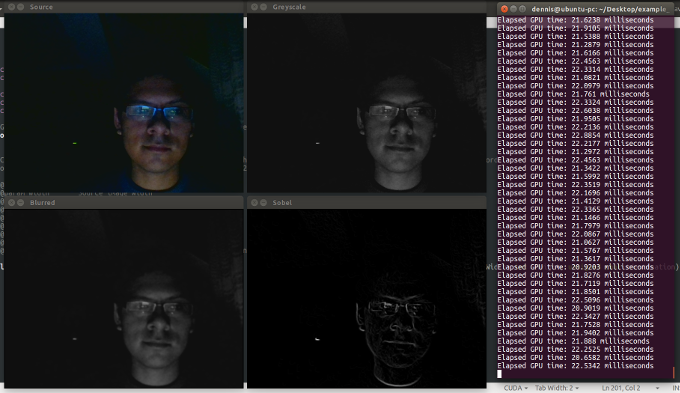
cv::imshow("Source", frame);
cv::imshow("Greyscale", source);
cv::imshow("Blurred", blurred);
cv::imshow("Sobel", edges);
// Spin
if(cv::waitKey(1) == 27) break;
}
// Exit
cudaFreeHost(source.data);
cudaFreeHost(blurred.data);
cudaFreeHost(edges.data);
cudaFree(deviceGradientX);
cudaFree(deviceGradientY);
return 0;
}
Compiling and executing
Create the file
CUDACC=nvcc
RM=rm -rf
SOURCES=imgproc.cu
OBJECTS=$(SOURCES:.cu=.o)
LDFLAGS=-lopencv_core -lopencv_highgui -lopencv_imgproc
.SUFFIXES: .cu .o
all: imgproc
imgproc: $(OBJECTS)
$(CUDACC) $(LDFLAGS) $(OBJECTS) -o imgproc
clean:
$(RM) *.o imgproc
.cu.o:
$(CUDACC) $< -c -o $@
Then, compile:
$ make
Finally, run:
$ ./imgproc
The last command should show: