Load Caffe framework models using OpenCV 3.3.0 and Python
Load Caffe framework models using OpenCV
In this tutorial you will learn how to use dnn module for image classification by using GoogLeNet and SqueezeNet trained networks from Caffe model zoo.
We will demonstrate results of this example on the following picture.

Source Code
This code was tested on Python 2.7 and works fine. We will be using the next code, that can be downloaded here: [link].
# USAGE
# python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt --model models/bvlc_googlenet.caffemodel --labels synset_words.txt --image images/barbershop.png
# python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt --model models/squeezenet_v1.0.caffemodel --labels synset_words.txt --image images/barbershop.png
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-l", "--labels", required=True,
help="path to ImageNet labels (i.e., syn-sets)")
args = vars(ap.parse_args())
# load the class labels from disk
rows = open(args["labels"]).read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]
# load the input image from disk
image = cv2.imread(args["image"])
# our CNN requires fixed spatial dimensions for our input image(s)
# so we need to ensure it is resized to 224x224 pixels while
# performing mean subtraction (104, 117, 123) to normalize the input;
# after executing this command our "blob" now has the shape:
# (1, 3, 224, 224)
blob = cv2.dnn.blobFromImage(image, 1, (224, 224), (104, 117, 123))
# load our serialized model from disk
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
# set the blob as input to the network and perform a forward-pass to
# obtain our output classification
net.setInput(blob)
start = time.time()
preds = net.forward()
end = time.time()
print("[INFO] classification took {:.5} seconds".format(end - start))
# sort the indexes of the probabilities in descending order (higher
# probabilitiy first) and grab the top-5 predictions
preds = preds.reshape((1, len(classes)))
idxs = np.argsort(preds[0])[::-1][:5]
# loop over the top-5 predictions and display them
for (i, idx) in enumerate(idxs):
# draw the top prediction on the input image
if i == 0:
text = "Label: {}, {:.2f}%".format(classes[idx],
preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# display the predicted label + associated probability to the
# console
print("[INFO] {}. label: {}, probability: {:.5}".format(i + 1,
classes[idx], preds[0][idx]))
# display the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
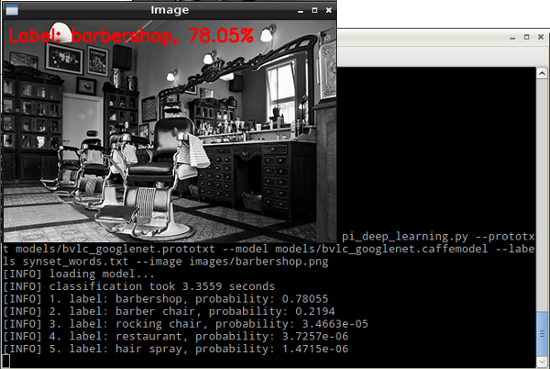
Run GoogleNet
$ cd ~/Desktop/pi_deep_learning
$ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt --model models/bvlc_googlenet.caffemodel --labels synset_words.txt --image images/barbershop.png
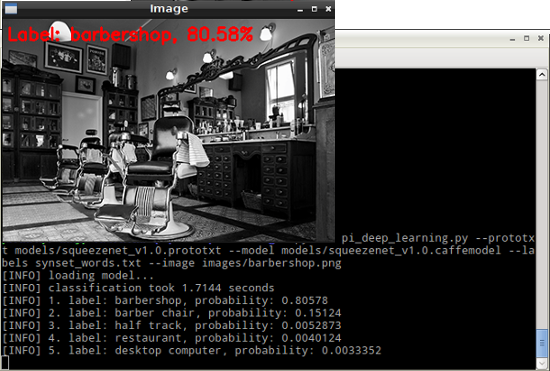
Run SqueezeNet
$ cd ~/Desktop/pi_deep_learning
$ python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt --model models/squeezenet_v1.0.caffemodel --labels synset_words.txt --image images/barbershop.png
Resources
- https://www.pyimagesearch.com/2017/10/02/deep-learning-on-the-raspberry-pi-with-opencv/.